机器学习引言
机器学习观点
拿到数据之后,构建机器学习算法第一步:观察数据,总结规律
不正确观点:收集足够多数据,从网上随便下载一个开源算法模型,直接将数据扔进模型中训练,就可能获得很好的结果(大多数不正确)
对数据有足够的感性认识,才能设计出好的算法以及认识算法的性能极限
- 设计算法:思考一个任务的经验E和性能指标P是什么
- 一个解决分类的问题稍微加以改造就可以解决回归问题,反之亦然,因为连续与离散是可以转换的
- 机器学习的重点不是提取特征,而是假设在已经提取好特征的前提下,如何构造算法获得更好的性能
- 提取特征很重要,不同媒质不同任务,提取特征的方式千变万化
- 维度与标准决定了我们要用机器学习,维度:人对超过二维的数据难以想象,标准:对某些区域的划分是不一样的
- 机器学习是典型的最优化问题,数学在现代化机器学习中占有重要的作用
机器学习定义
ARCHUR SAMUEL
1 | |
显著式编程
- 通过人为预先定义出规律,告诉计算机实现一一对照区别。
- 劣势:人为帮计算机规划所处的环境,将环境、规律调查得一清二楚
非显著式编程
- 事先并不约束计算机总结出什么规律,只给大量数据,编写程序让计算机自己挑出能分辨事物的规律,总结不同事物的区别
- 规定在特定环境下,做一些行为带来的收益,将收益称为收益函数
- 规定了收益函数后,让计算机去自己找最大化收益函数的行为
- 优势:通过数据、经验自动学习
TOM MITSHELL
1 | |
特点
- Experience越来越多,Performance Measure也会越来越高
- 更数学化,典型的最优化问题
发现
- 数学在现代化机器学习中占有重要的作用
机器学习分类
现在的强化学习利用到了监督学习,如ALPHAGO,先通过监督学习获得初试围棋程序,再将初试围棋程序进行强化学习
监督学习
- 经验E是完全由人搜集起来输入进计算机
- 为训练数据打标签,此时经验E为:训练样本和标签的集合
- 垃圾邮件识别,教计算机自动识别某个邮件识别是垃圾邮件
- 人脸识别,教计算机通过人脸的图像识别这个人是谁
传统监督学习
每一个训练数据都有对应的标签
- 支持向量机
- 人工神经网络
- 深度神经网络
非监督学习
所有训练数据都没有对应的标签
- 聚类
- EM算法
- 主成分分析
半监督学习
训练数据中一部分有标签,一部分没有标签(如何用少量标注数据与大量未标注数据,获得更好的机器学习算法)
强化学习
- 经验E是由计算机与环境互动获得的
- 产生行为,定义这些行为的收益函数(Reward function),改变自己行为模式去最大化收益函数
- 计算机通过与环境的互动,逐渐强化自己的行为模式
- 教计算机下棋
- 无人驾驶,教计算机自动驾驶汽车,从一个指定地点到另一个指定地点
机器学习算法过程
识别尿沉中的红白细胞

可能被观察到的区别
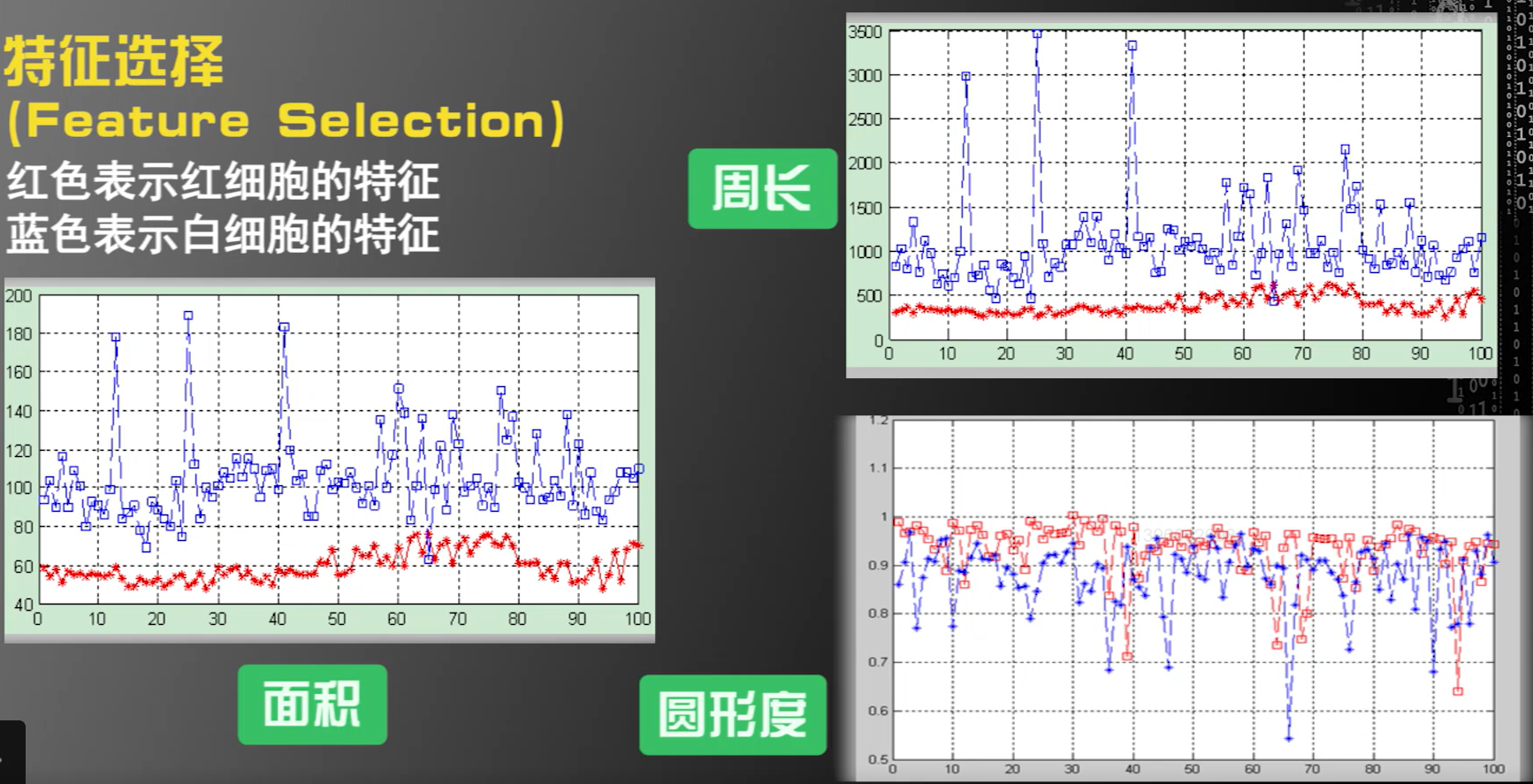
- 平均来说,白细胞面积比红细胞大
- 白细胞没有红细胞圆
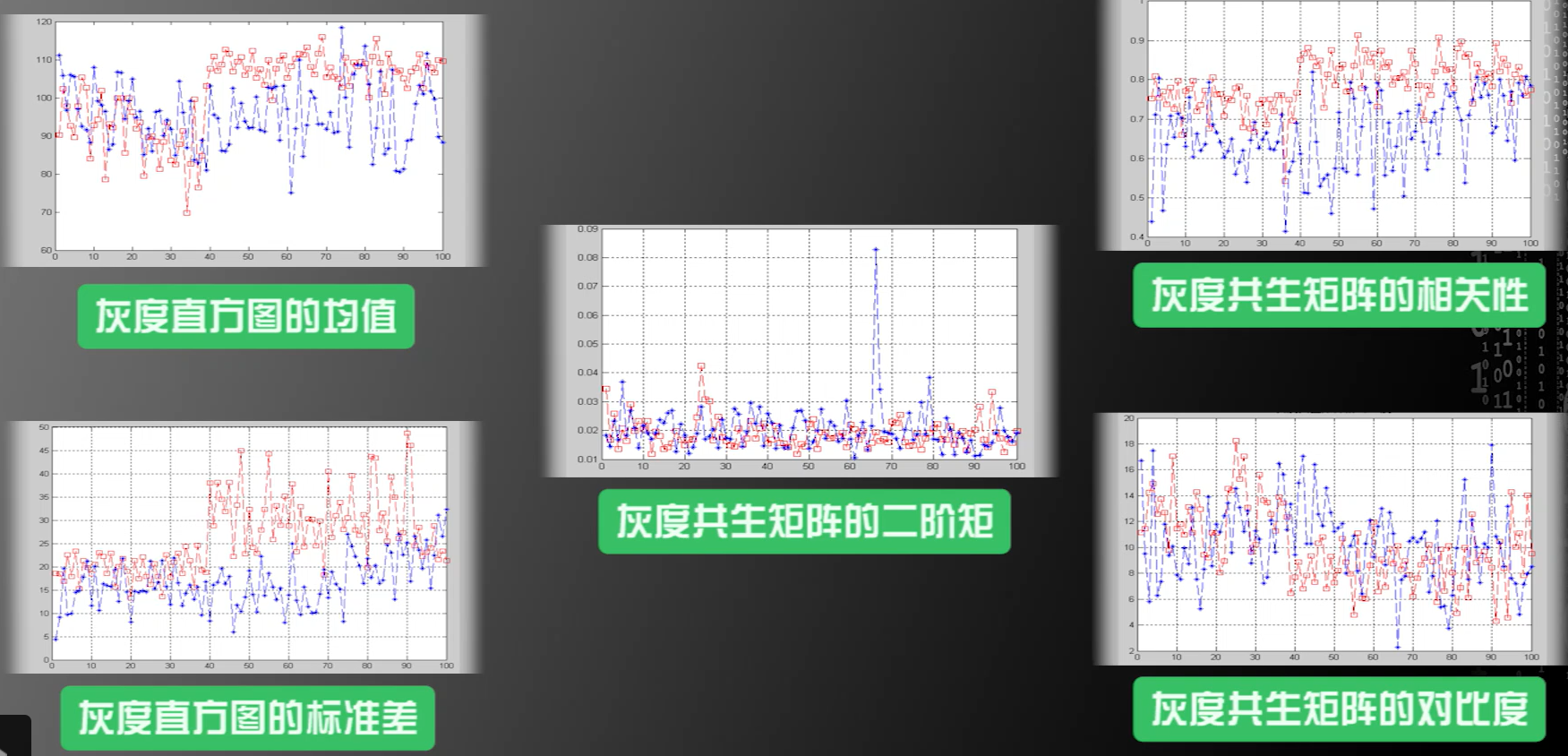
- 白细胞内部纹理比红细胞粗糙
第一步:提取特征
通过训练样本获得的,对机器学习任务有帮助的多维度的特征数据
很重要,提取了好的特征,(即使算法不是很好)也能获得不错的性能
提取了差的特征,不可能获得好的性能
细胞的面积 圆形度 表面粗糙程度
提取面积特征方法
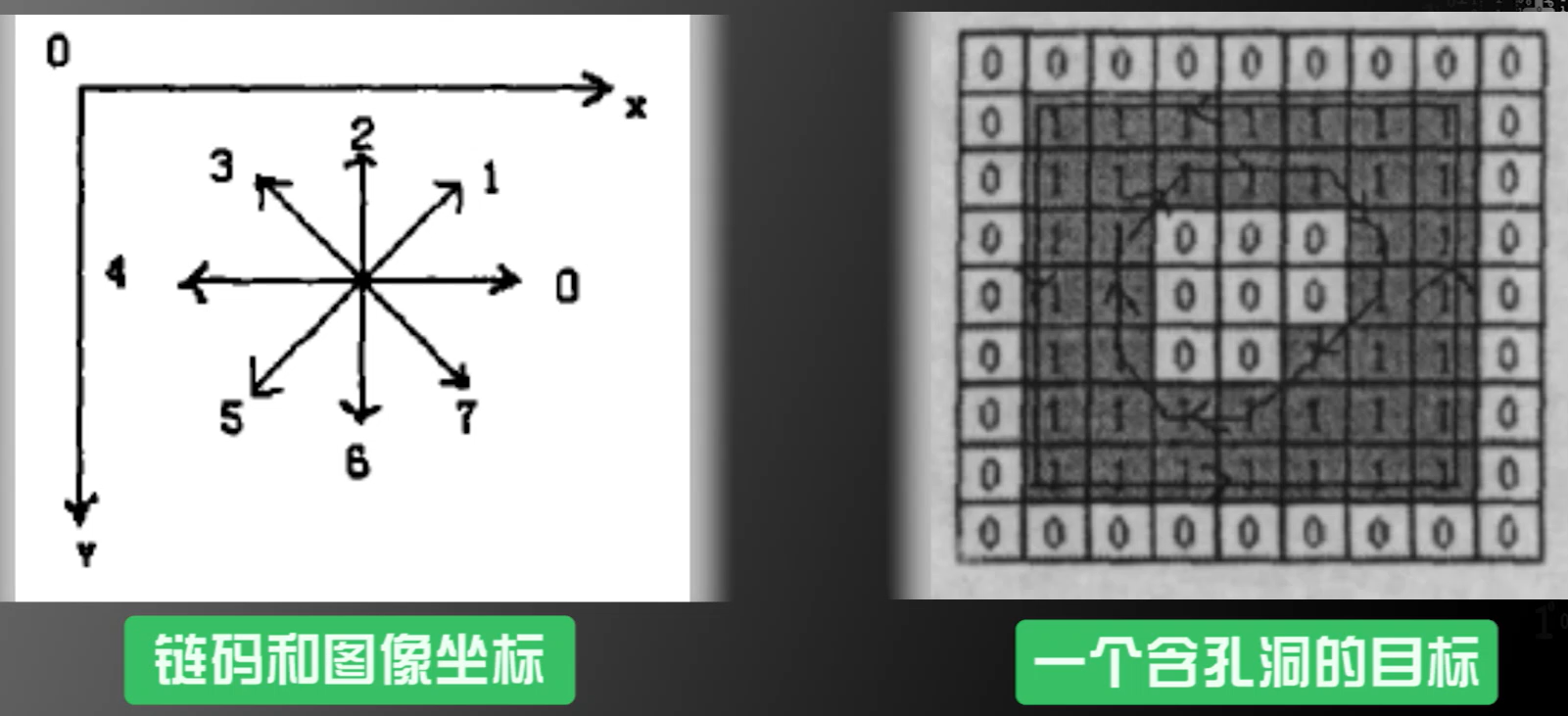
第二步:特征选择
只选择面积与周长作为区分,来构建机器学习系统,后面归一化一下
第三步:设计算法
支持向量机
- 线性内核
- 多项式内核
- 高斯径向基函数核
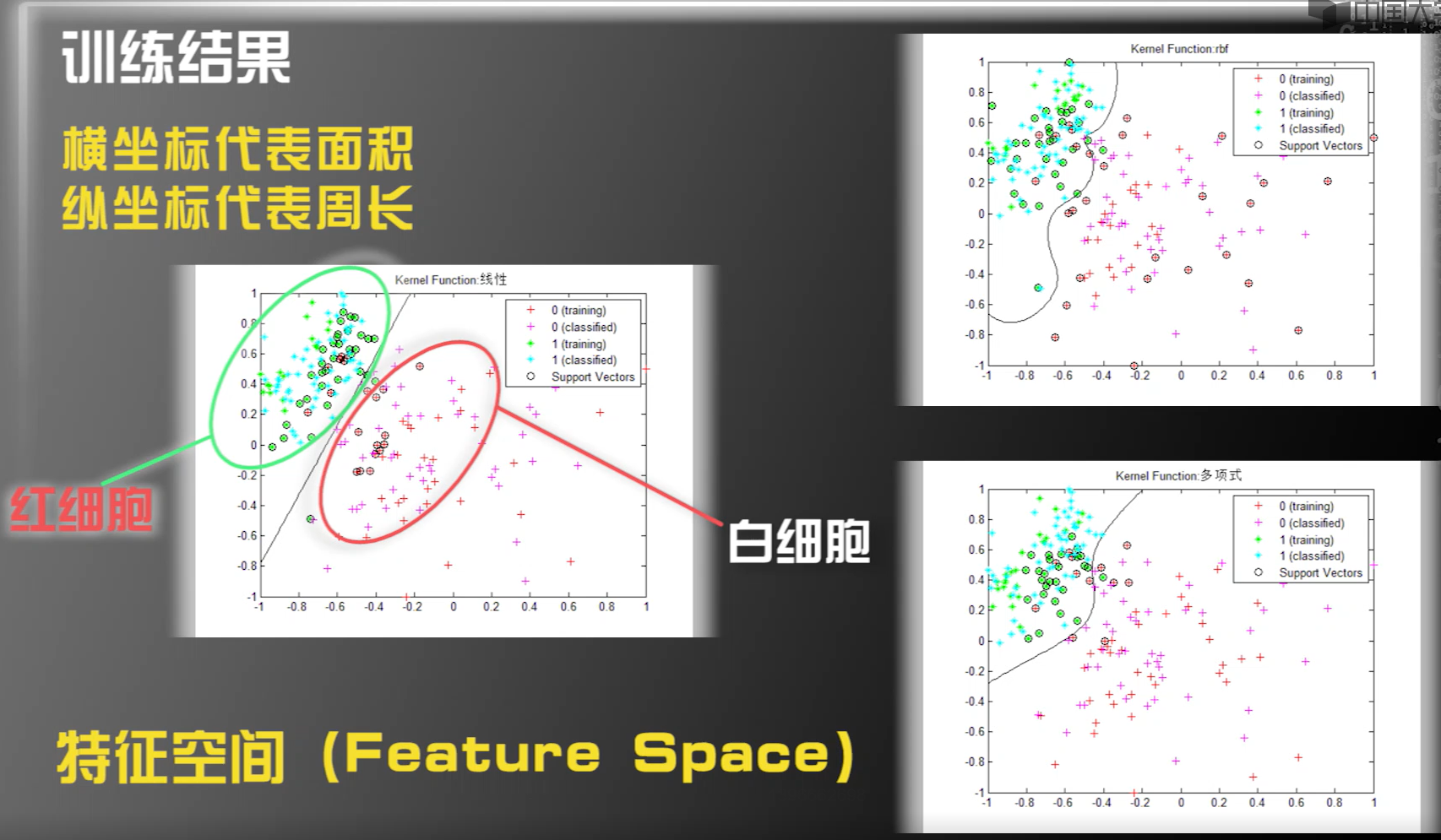
第四步:训练结果
获得训练库准确率
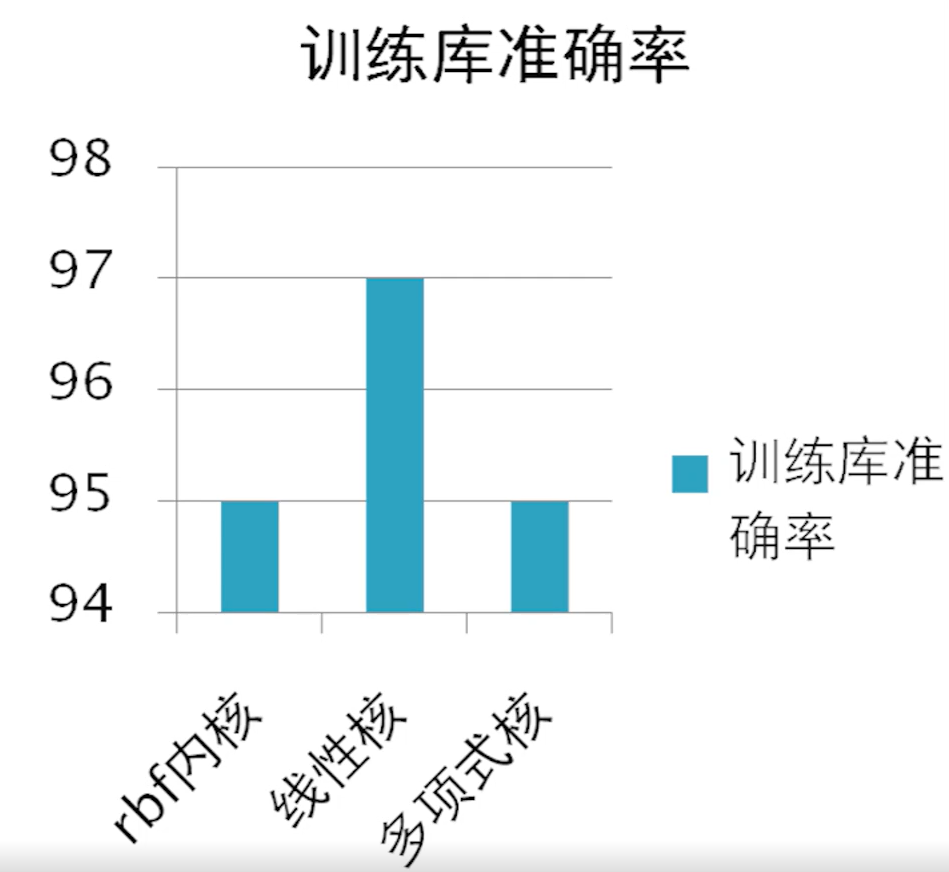
机器学习算法比较
没有免费午餐定理
任何一个预测函数,如果在一些训练样本上表现好,那么必然在另一些训练样本上表现不好,如果不对数据在特征空间的先验分布有一定假设,那么表现好于表现不好的情况一样多。
在设计机器学习算法的时候有一个假设:在特征空间上距离接近的样本,他们属于同一个类别的概率会更高。
道理是从以前的事实中来的。通过类比推广到对未来的预测。
总结
不对特征空间的先验分布有假设,所有算法的表现都一样。
机器学习的本质:从有限的已知数据,在复杂的高维特征空间中预测未知样本的属性和类别。然而,我们不知道未知样本在哪里、性质如何,因此,再好的算法也存在犯错误的风险。
机器学习作业
编程大作业
- 人脸识别
- 人脸性别年龄估计
- 五子棋对战程序
- 水果识别
- 人脸特征点检测
- 语种识别
- 视频行为识别
机器学习引言
http://example.com/2024/05/19/20240519_MachineLearning_Introduction/