支持向量机
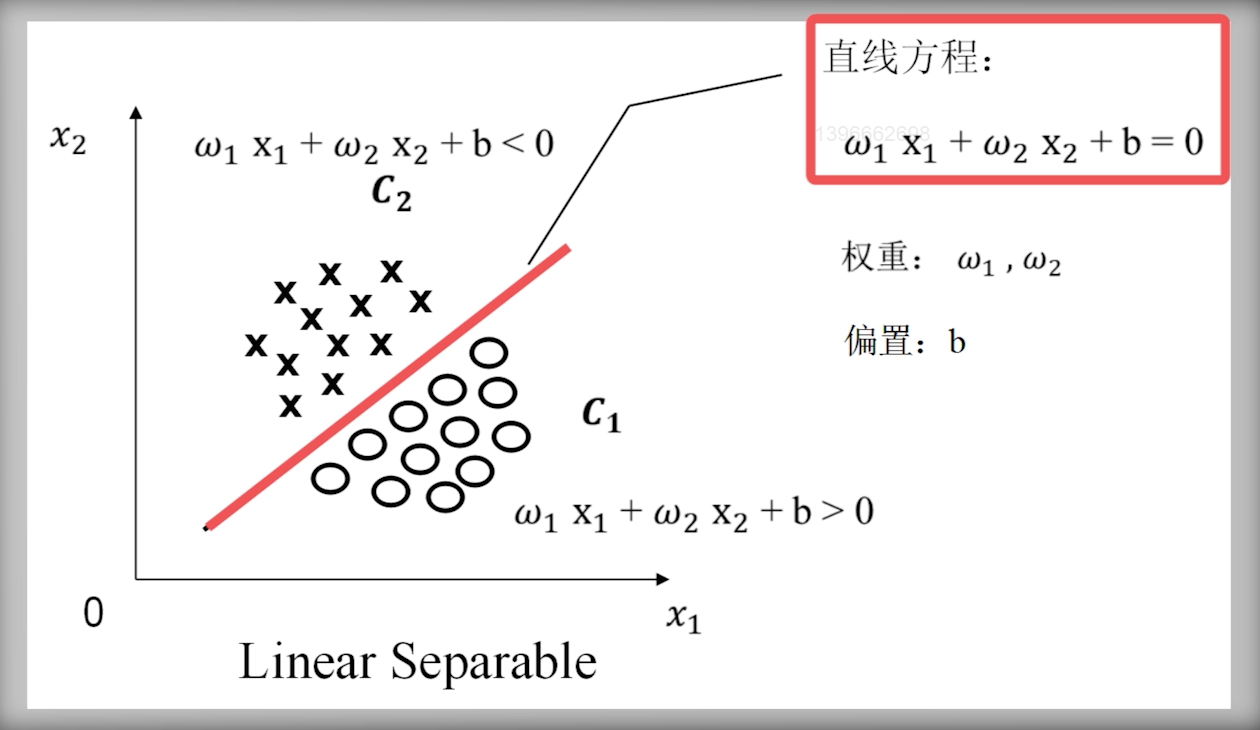
线性可分定义
二维平面中,存在一条直线可以把圆圈和叉分开;三维平面中,存在一个面可以把圆圈和叉分开;四维及以上,超平面。
假设
我们有N个训练样本和他们的标签${(X_1,y_1),(X_2,y_2),…,(X_N,y_N)}$,
其中$X_i = [x_{i1},x_{i2}]^T$,$y_i = {+1,-1}$,这样,$y_i = +1$时,$X_1$属于$C_1$
数学定义
线性可分的严格定义:一个训练样本集${(X_i,y_i),…,(X_N,y_N)}$,在i=1~N线性可分,是指存在$(w_1,w_2,b)$,使得对i = 1~N,有:
- 若$y_i = +1$,则$\omega_1x_{i1}+\omega_2x_{i2}+b > 0$
- 若$y_i = -1$,则$\omega_1x_{i1}+\omega_2x_{i2}+b < 0$
向量形式定义
假设:$X_i={\begin{bmatrix}X_{i1}\\X_{i2}\end{bmatrix}}^T \omega={\begin{bmatrix}\omega_{1}\\\omega_{2}\end{bmatrix}}^T$
- 若$y_i = +1$,则$\omega^TX_{i}+b > 0$
- 若$y_i = -1$,则$\omega^TX_{i}+b < 0$
最简化形式
如果 $y_i=+1$或-1
一个训练样本集${(X_i,y_i)}$,在i = 1~N线性可分,是指存在(\omega,b),使得对i = 1~N,有:
$$y_i(\omega^TX_i+b)>0 $$问题描述
解决线性可分问题
在无数多个分开各个类别的超平面中,到底哪一个最好?
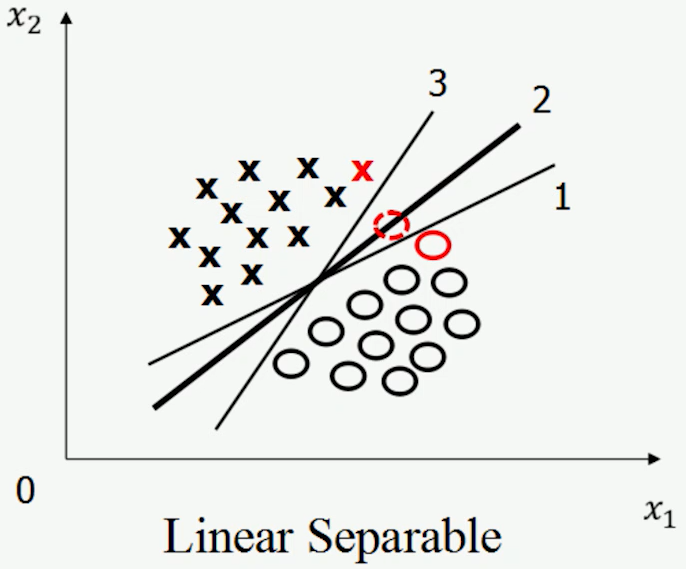
基于对训练样本先验分布有一定假设,如假设训练样本的位置在特征空间上有测量误差,图中二号线对训练样本误差的容忍程度是最高的,相比1号线和3号线更能抵御训练样本位置的误差
2号线是怎么画出来的?
基于最优化理论,间隔最大的是2号线,(确定唯一)取上下两个平行线中间
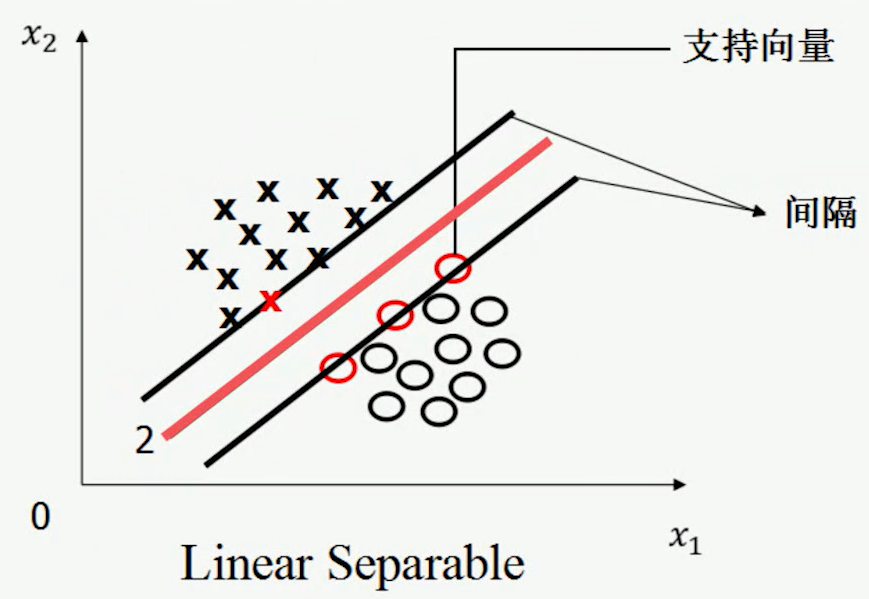
- 该直线分开了两类
- 该直线最大化间隔
- 该直线处于间隔的中间,到所有支持向量距离相等
再将线性可分问题中获得的结论推广到线性不可分情况
优化问题
如何用严格的数学,寻找最有分类超平面的过程,写成一个最优化的问题
假定训练样本集是线性可分的,支持向量机需要的是最大化间隔(MARGIN)的超平面(离两边所有支持向量的距离相等)
要求
已知:训练样本集{(x_i,y_i)},i=1到N;
待求:(w,b)
最小化
${1 \over 2}{||\omega||}^2$
为什么看事实2

限制条件
$y_i(w^Tx_i+b)>=1,(i=1 ~ N)$
在支持向量机(Support Vector Machine, SVM)中,约束条件$y_i (\omega^T x_i + b) \geq 1 ) (其中 (i = 1, 2, \ldots, N)$是用于确保数据点被正确分类并且在超平面边界以外有一定的间隔。具体解释如下:
定义符号:
- $\omega$是超平面的法向量。
- $x_i$是第 $i$ 个样本点。
- $b$是超平面的偏置项。
- $y_i$ 是第$i$个样本点的类别标签,取值为$\pm1$。
支持向量机的目标:
SVM的目标是找到一个能够最大化分类间隔(Margin)的超平面。分类间隔定义为到最近数据点的距离。约束条件解释:
约束条件$y_i (\omega^T x_i + b) \geq 1$用于确保所有训练样本点被正确分类,并且离超平面至少有一个单位的距离。$y_i$协调超平面的左右。详细解释如下:- 当 $y_i = 1$ 时,约束条件为$\omega^T x_i + b \geq 1$。这意味着正类样本点$x_i $应该位于超平面的正侧并且到超平面的距离至少为 1。
- 当 $y_i = -1 $时,约束条件为$\omega^T x_i + b \leq -1$。这意味着负类样本点$x_i$应该位于超平面的负侧并且到超平面的距离至少为 1。
最大化间隔:
通过这些约束条件,我们确保了最小间隔为 1 的正确分类,同时目标是最大化此间隔。在优化过程中,我们会最小化 $\frac{1}{2} |\omega|^2$,等价于最大化间隔,因为间隔与$|\omega|$成反比。几何解释:
通过添加这个约束条件,我们可以确保找到的超平面不仅能正确分类所有样本点,还能最大化分类的鲁棒性,即使数据点在决策边界附近有少量扰动,也能保证分类的准确性。
综上所述,约束条件$y_i (\omega^T x_i + b) \geq 1$是支持向量机的重要组成部分,它保证了正确分类并且尽可能地增大分类间隔,从而提高模型的泛化能力。
事实
事实1
$\omega^Tx+b = b$与$(a\omega^T)x+(ab)=0$是同一个超平面。($a \neq 0$)
事实2
一个点$X_0$到超平面$\omega^Tx+b = 0$的距离$d = {|\omega^Tx_0+b| \over ||\omega||}$
一个点$(x_0,y_0)$到超平面$\omega_1x+\omega_2y+b = 0 $的距离$d = {|\omega_1x_0 + \omega_2y_0 + b| \over \sqrt {\omega_1^2 + \omega_2^2}}$
平面方程:给定平面$ \alpha $的方程为:
$Ax + By + Cz + D = 0 $点和法向量:点 $P_0(x_0, y_0, z_0) $是要计算到平面距离的点,平面的法向量为 $\vec{n} = (A, B, C) $。
距离公式的推导:
- 选择平面上的一点 $P_1(x_1, y_1, z_1)$ 作为参考点。
- 向量 $\vec{P_1P_0} $表示从点 $ P_1 $ 到点 $ P_0 $的向量,其表示为:
$\vec{P_1P_0} = (x_0 - x_1, y_0 - y_1, z_0 - z_1) $ - 点 $P_0 $到平面的距离 $d$等于向量$\vec{P_1P_0}$ 在法向量 $\vec{n} $上的投影的绝对值,公式为:
$d = \frac{|\vec{P_1P_0} \cdot \vec{n}|}{|\vec{n}|}$ - 计算向量点积$\vec{P_1P_0} \cdot \vec{n}$:
$ \vec{P_1P_0} \cdot \vec{n} = A(x_0 - x_1) + B(y_0 - y_1) + C(z_0 - z_1)$ - 计算法向量$\vec{n}$的模长:
$ |\vec{n}| = \sqrt{A^2 + B^2 + C^2}$
化简距离公式:
- 由于点$P_1$在平面上,所以 $Ax_1 + By_1 + Cz_1 + D = 0$,因此$D = -(Ax_1 + By_1 + Cz_1)$。
- 将上面的结果代入到公式中,得到:
$d = \frac{|A(x_0 - x_1) + B(y_0 - y_1) + C(z_0 - z_1)|}{\sqrt{A^2 + B^2 + C^2}}$ - 将 ( P_1(x_1, y_1, z_1) ) 替换成点 ( P_0(x_0, y_0, z_0) ) 的坐标,公式变为:
$d = \frac{|Ax_0 + By_0 + Cz_0 + D|}{\sqrt{A^2 + B^2 + C^2}}$
因此,点 $P_0(x_0, y_0, z_0)$到平面$Ax + By + Cz + D = 0$的距离公式为:
$d = \frac{|Ax_0 + By_0 + Cz_0 + D|}{\sqrt{A^2 + B^2 + C^2}}$
难点
- 用a去缩放$/omega b$
- $(/omega , b)$->$(a/omega , ab)$
- 最终使在支持向量$x_0$上有$|/omega^Tx_0 + b| = 1$,而在非支持向量上$ |/omega^Tx_0 + b| > 1$
- 根据事实2,支持向量机$x_0$到超平面距离将会变为:$d = \frac{|\omega^T x_0 + b|}{|\omega|} = \frac{1}{|\omega|}$
- 最大化支持向量到超平面的距离等价于最小化||/omega||
二次规划
定义
目标函数是二次项

限制条件是一次项
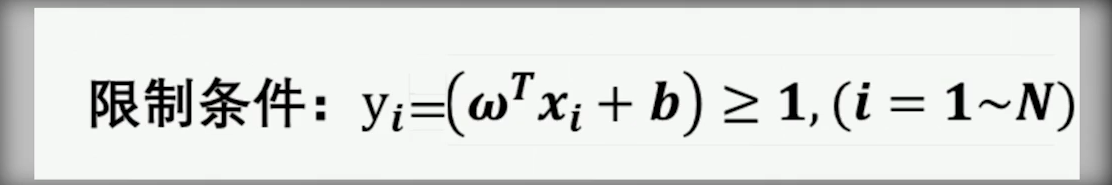
这种凸优化问题要么无解,要么只有唯一的最小值解,可以应用梯度算法来解
线性不可分情况
不存在$\omega$和$b$满足上面所有N个限制条件
需要放松限制条件(基本思路)
- 对每个训练样本及标签$(X_i,Y_i)$
- 松弛变量$\delta_i$
- 限制条件改写:$y_i(\omega^TX_i + b) \ge 1 - \delta_i (i = 1\sim N)$
改造后的支持向量机优化版本
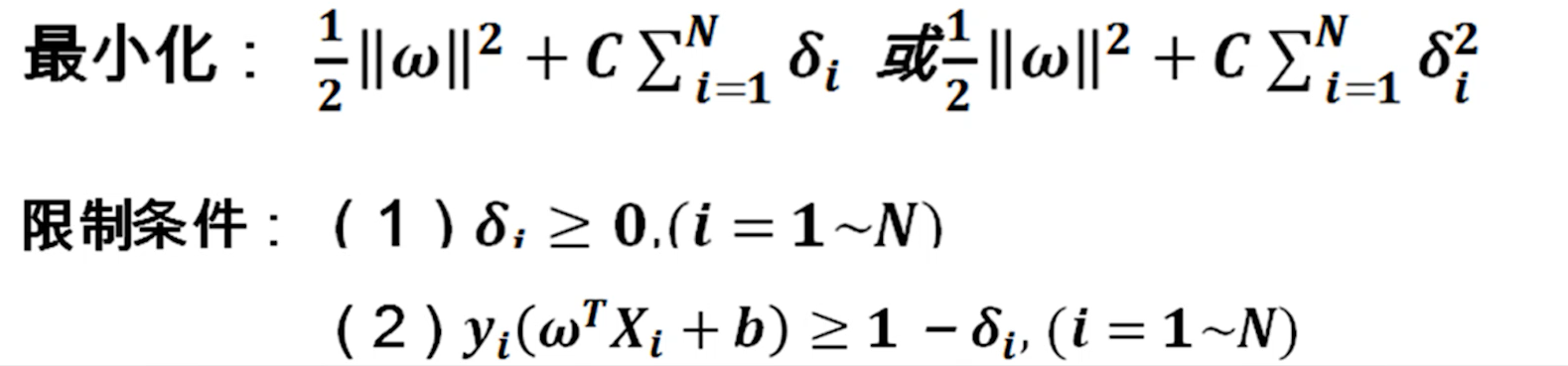
人为实现设定的参数叫做算法的超参数,不断变化C的值,同时测试算法的识别率,选取超参数C
支持向量机是超参数很少的算法模型
例子
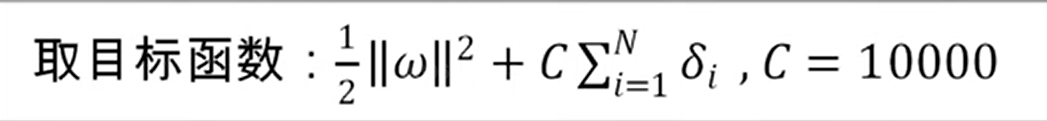
C很大,会迫使所有的$\delta_i$趋于0,超平面和线性可分情况保持基本一致
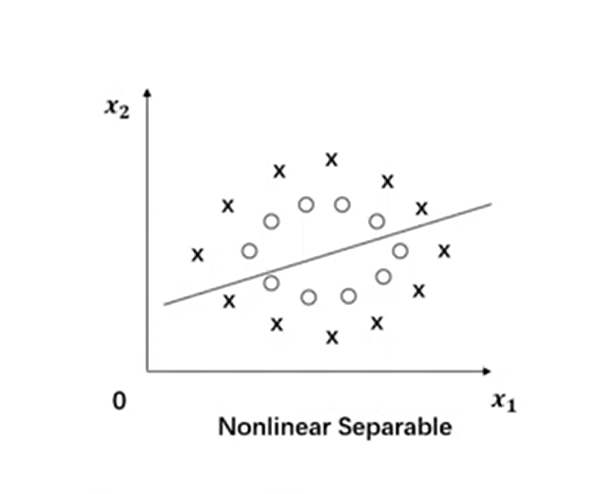
未达到求解目的(类型:所有的圆圈被所有的叉包围了),这个解远远不能让人满意,分错了一半训练样本
问题
我们是假设分开两类的函数是线性的,线性模型的表现力是不够的,无论我们如何取直线,都是不好的,应该扩大可选函数范围,使得其超越线性
课后思考
请问:在这个例子中,你能否设计出一个这样的非线性变换,将这个分类问题转化为线性可分?
要将这个非线性可分的分类问题转化为线性可分,可以考虑使用核函数或特征变换。一个常见的非线性变换方法是将输入空间映射到一个更高维的特征空间
对于这个例子,可以使用径向基函数(BRF)核函数或多项式核函数来进行非线性变换
特征变换的示例
假设我们有两个特征$x_1$和$x_2$,可以将其转换为新的特征z,例如:
$ z_1 = x_1^2$
$ z_2 = x_2^2$
$ z_3 = x_1 \cdot x_2$
这种变换可以将原始的二维非线性可分数据映射到三维空间,使得在这个新空间中变得线性可分
核方法
另一种方法是使用核函数,例如径向基函数核(RBF核):
$K(x_i,x_j) = exp(\gamma||x_i - x_j||^2)$
通过这种方法,可以隐式地将数据映射到一个高维空间,而无需显示地计算特征变换
示例代码
1 | |
思维方式
观察数据分布
首先,我们需要仔细观察数据的分布。通过可视化数据(如散点图),我们可以识别出数据的结构和模式。在你的例子中,数据呈现出同心圆的分布,明显不是线性可分的。
找到适合的特征变换
为了使数据变得线性可分,我们需要找到一种变换方式,使得数据在新的特征空间中分布更适合线性分类。常见的思路包括:
- 多项式变换:对于同心圆分布的数据,平方或交叉项(如$x_1^2 、x_2^2 和x_1 \cdot x_2$)可能会有帮助,因为这些变换可以捕捉到数据的非线性关系。
- 非线性变换:使用核方法(如RBF核)来隐式地将数据映射到高维空间,其中数据可能会变得线性可分。
数学和几何直觉
通过数学和几何直觉,我们可以推断出一些变换可能会使数据线性可分。例如,考虑二次多项式变换。对于同心圆数据,使用平方项可以将圆形分布的数据转换为线性可分的数据。这是因为平方变换会放大远离原点的数据点的特征,使得数据点在新的空间中分布得更加分散。
实验和验证
即使有数学和几何直觉的支持,我们仍然需要通过实验和验证来确认选择的特征变换是否有效。这可以通过以下步骤实现:
- 选择变换:选定一种或几种可能的特征变换。
- 应用变换:将原始数据应用选定的变换。
- 训练模型:在变换后的特征空间中训练线性分类模型。
- 验证结果:评估模型的表现,查看其是否能够有效分类数据。
低维到高维的映射
在扩大可选函数范围方面独树一帜
特征空间由低维映射到高维,用线性超平面对数据进行分类

构造一个二维到五维的映射$\varphi(x)$

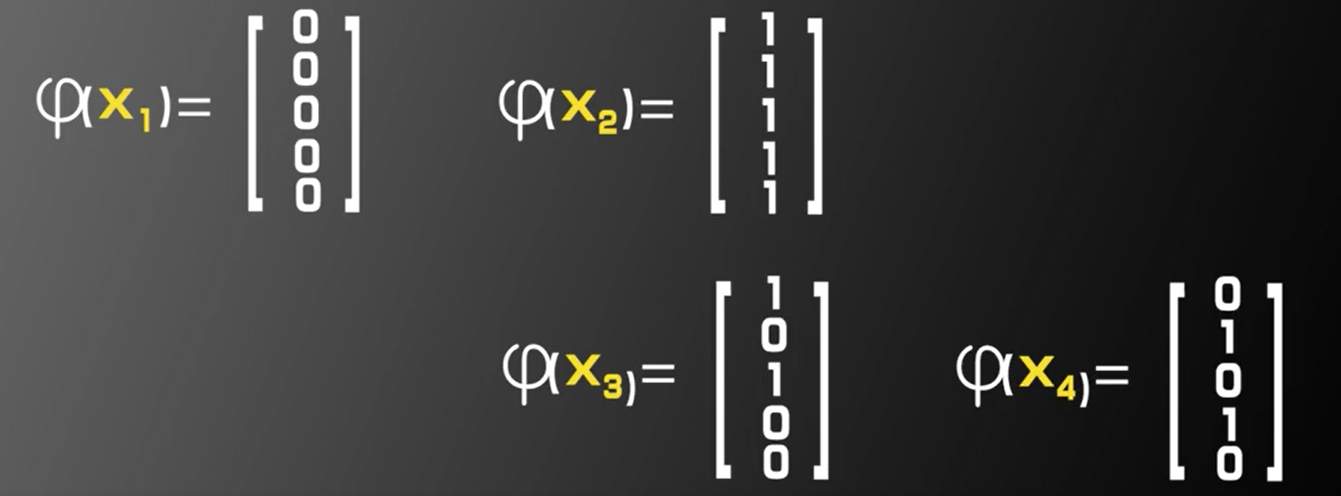
- 此时线性可分
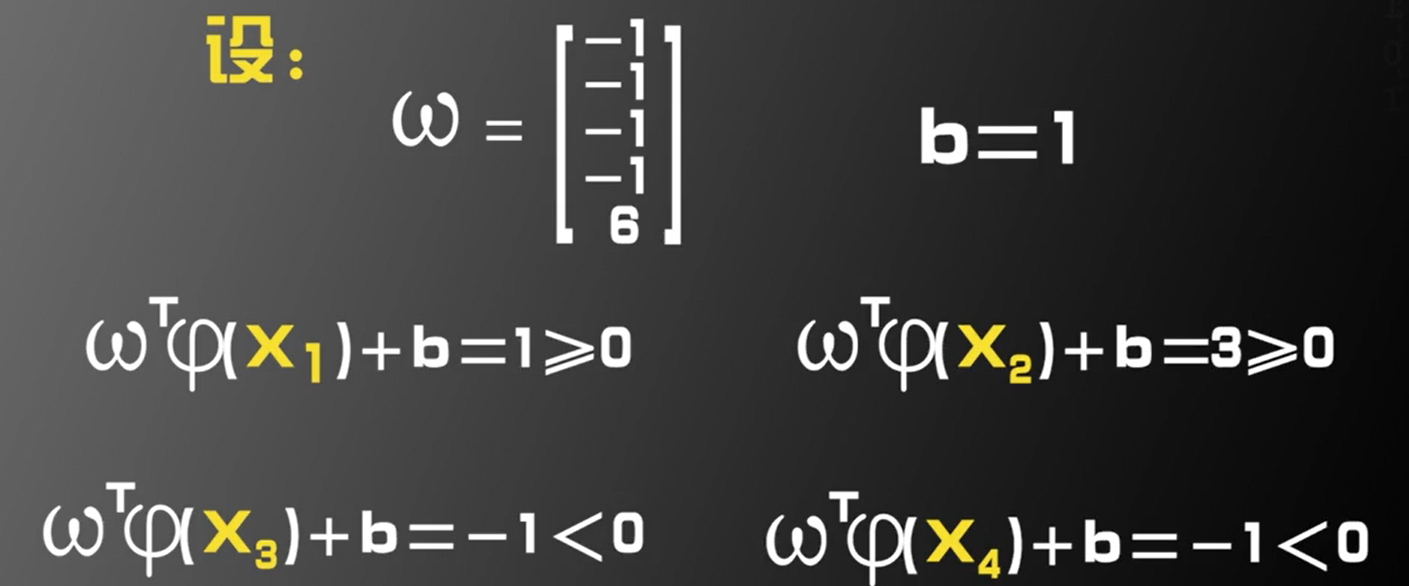
假设:
在一个M维空间上随机取N个训练样本
随机的对每个训练样本赋予标签+1或-1
假设:
这些训练样本线性可分的概率为P(M)
当M趋于无穷大时 P(M)=1
优化问题
前$\omega维度与X_i$维度相同 $\omega$维度与$\varphi(x_i)$相同
高维情况下优化问题的解法和低维情况下是完全类似的
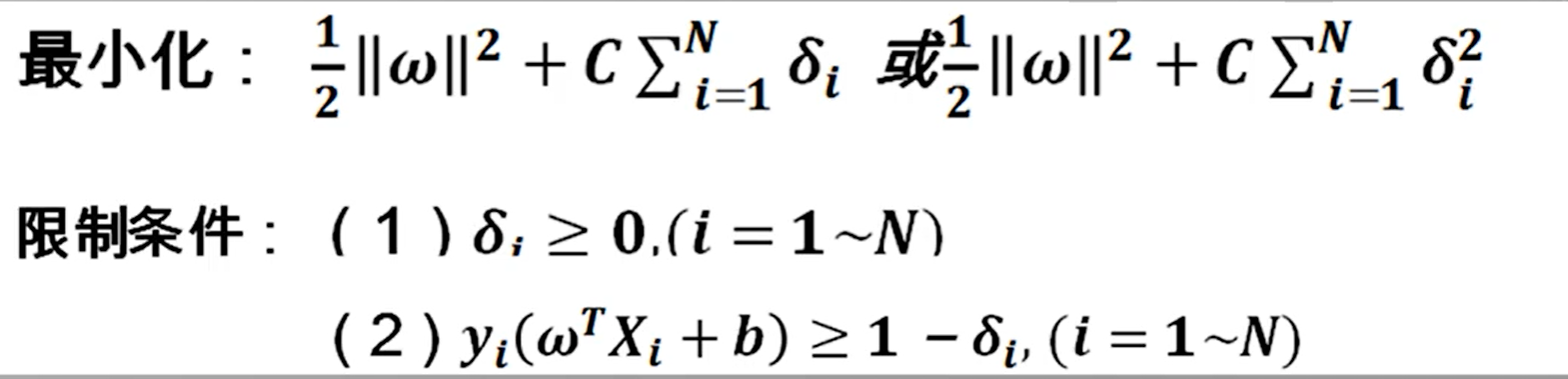

优化问题的凸性
凸优化问题的定义
- 一个优化问题是凸的,如果其目标函数是凸函数,并且约束条件也定义了一个凸集
- 凸函数的一个重要性质是其任意局部最优解也是全局最优解,这使得优化问题易于求解
SVM优化目标
支持向量机的目标是找到一个分离超平面,使得两个类别的间隔最大化。对于线性 SVM,其优化问题可以表示为:
$\min_{w,b}{1\over2}||w||^2 $
其中 w 是权重向量,b* 是偏置。这个目标函数是凸的。
核函数的定义
$K(X_1,X_2) = \varphi(X_1)^T\varphi(X_2)$完成对测试样本类别的预测
核方法和核矩阵
核函数的引入
- 在处理非线性可分问题时,SVM使用核函数$K(X_i,X_j)$将数据映射到高维特征空间,以实现线性可分
- 核函数K计算两个输入数据点$X_i和X_j$在高维空间中的内积,而不需要显示地进行高维映射
核矩阵
- $K_{ij} = K(X_i,X_j)$
- 核矩阵K是一个对称矩阵,其元素是核函数在数据点间计算的值
半正定性的重要性
半正定性定义
- 一个对称矩阵K是半正定的,如果对于任何向量z,都有$z^TKz \ge 0$
核矩阵的半正定性与凸性
- 对于SVM的优化问题,目标函数包含核矩阵K。如果K是半正定的,那么相应的二次规划问题也是凸的
- 半正定性保证了目标函数在所有方向上的二次型都是非负的,即目标函数是凸函数
唯一解的存在性
- 在凸优化问题中,目标函数的任何局部最优解也是全局最优解。因此,确保核矩阵是半正定的,能保证SVM优化问题有唯一解。
核函数与$\varphi(x)$的关系
核函数K和映射$\varphi$是一一对应的,核函数的形式不能随意取,需满足为一定条件才能分解为两个$\varphi$内积的形式
Mercer’s Theorem定理

已知$\varphi$求K
假设:$\varphi(x)$是一个将二维向量映射为三维向量的映射

假设有两个二维向量

已知K求$\varphi()$
假设:

假设:
$X = [x_1,x_2]^T$

$K(X_1,X_2)$就是前面那个形式
原问题和对偶问题
定义
原问题
- 最小化:$f(\omega)$
- 限制条件
- $g_i(\omega) \le 0 i = 1 \sim K$
- $h_i(\omega) = 0 i = 1 \sim m$
对偶问题
$ L(\omega, \alpha, \beta) = f(\omega) + \sum_{i=1}^{K} \alpha_i g_i(\omega) + \sum_{i=1}^{K} \beta_i h_i(\omega) $
$ = f(\omega) + \alpha^T g(\omega) + \beta^T h(\omega) $
其中
$ \alpha = \begin{bmatrix} \alpha_1, \alpha_2, \ldots, \alpha_K \end{bmatrix}^T $
$ \beta = \begin{bmatrix} \beta_1, \beta_2, \ldots, \beta_M \end{bmatrix}^T $
$ g(\omega) = \begin{bmatrix} g_1(\omega), g_2(\omega), \ldots, g_k(\omega) \end{bmatrix}^T $
$ h(\omega) = \begin{bmatrix} h_1(\omega), h_2(\omega), \ldots, h_m(\omega) \end{bmatrix}^T $
最大化:$\theta(\alpha,\beta) = \inf L(\omega,\alpha,\beta)$,所有定义域内的$\omega $, 使得L最小
限制条件:$\alpha_i \ge 0, i = 1 \sim K$
定理一
如果$\omega$是原问题的解,$(\alpha^\ast,\beta^\ast)$是对偶问题的解则有:
$f(\omega^\ast) \ge \theta(\alpha^\ast,\beta^\ast)$
证明:$\theta(\alpha^\ast, \beta^\ast) = \inf L(\omega, \alpha^\ast, \beta^\ast)$
$\leq L(\omega^\ast, \alpha^\ast, \beta^\ast)$
$= f(\omega^\ast) + \alpha^{\ast T} g(\omega^\ast) + \beta^{\ast T} h(\omega^\ast)$
$\leq f(\omega^\ast)$
原问题的解总是大于对偶问题的解
对偶差距: $ f(\omega^\ast) - \theta(\alpha^\ast, \beta^\ast)$
对偶差距为大于等于零的函数
强对偶定理
如果$g(\omega)=A\omega+b,h(\omega)=C\omega+d$,$f(\omega)$为凸函数,则有$f(\omega^\ast) = \theta(\alpha^\ast,\beta^\ast)$,
则对偶差距为0。
- 原问题的目标函数是凸函数,限制条件是线性函数,那么$f(\omega^\ast) = \theta(\alpha^\ast,\beta^\ast)$
KKT条件
若 $f(\omega^{\ast}) = \theta(\alpha^{\ast}, \beta^{\ast})$,则定理一中必然能够推出,对于所有的 $i = 1 \sim K$,要么 $\alpha_i = 0$,要么 $g_i(\omega^{\ast}) = 0$。这个条件称为 KKT 条件。