语言模型和数据集
马尔可夫模型和n元语法
1. 背景:马尔可夫性假设
马尔可夫性假设是语言建模中的核心思想之一。
假设序列中当前状态只依赖于有限个历史状态,可以减少计算复杂性。
公式中提到的分布:
根据马尔可夫性假设简化为:
, 即,序列的下一个状态只依赖于当前状态,而与更久远的历史无关。
2. 公式解析与语法模型
(1) 通用的链式法则
- 根据链式法则,任意序列 可以展开为:
- 这是最完整的公式,假设每个词都可能依赖于前面所有的词。
(2) 简化公式:马尔可夫假设
根据不同阶的马尔可夫性假设,可以逐步简化:
一元语法(unigram)模型:
意义:忽略词与词之间的关系,适合简单统计和快速计算。
缺点:不能捕捉词与词之间的语法或上下文关系。
二元语法(bigram)模型:
意义:只考虑词对之间的关系,比如捕捉到「deep learning」这种词对的依赖性。
优点:比一元模型更能反映词之间的语法关系。
缺点:无法捕捉更长的上下文依赖。
三元语法(trigram)模型:
意义:能够捕捉三元词组之间的依赖性,比如「state of the」。
优点:能捕捉更长的依赖。
缺点:当序列长度较大时,计算复杂度仍然较高,且数据稀疏性更严重。
3. 示例
假设序列为:「I love deep learning」,概率计算如下:
一元语法模型:
二元语法模型:
三元语法模型:
4. 总结
- 一元语法假设独立性,计算简单,但无法捕捉任何上下文信息。
- 二元语法假设当前词只依赖前一个词,适合捕捉词对关系,计算效率较高。
- 三元语法扩展了依赖范围,但面临计算复杂度和数据稀疏的问题。
自然语言统计
1 | |
正如我们所看到的,最流行的词看起来很无聊, 这些词通常被称为停用词(stop words),因此可以被过滤掉。 尽管如此,它们本身仍然是有意义的,我们仍然会在模型中使用它们。 此外,还有个明显的问题是词频衰减的速度相当地快。 例如,最常用单词的词频对比,第10个还不到第1个的1/5。 为了更好地理解,我们可以画出的词频图:
1 | |
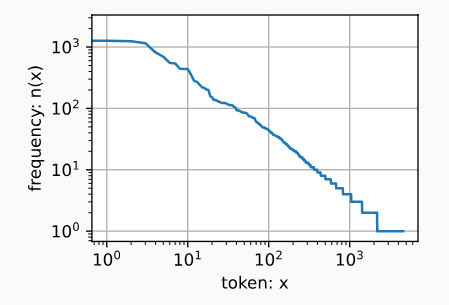
齐普夫定律 (Zipf’s Law)
齐普夫定律是一种描述自然语言中的词频分布规律的经验法则,它由语言学家乔治·齐普夫 (George Zipf) 提出。这一定律表明,在一段文本或语料中,单词的出现频率与其频率排名成反比。
公式
其中:
- f(r):单词的出现频率(词频)。
- r:单词的频率排名。
- s:幂指数(通常在自然语言中约为 1)。
- ∝:表示“成正比”。
可以简单表达为:
直观解释
- 自然语言文本中的单词分布非常不均匀。
- 高频词(如“the”、“of”、“and”)出现的次数远远多于低频词。
- 齐普夫定律的核心观点
- 排名为第 1 的单词(最高频单词)的出现次数,约等于排名第 2 的单词的 2 倍,约等于排名第 3 的单词的 3 倍,依此类推。
- 例如:
- 最高频单词出现 1000 次;
- 排名第 2 的单词出现约 500 次;
- 排名第 3 的单词出现约 333 次。
自然语言中的应用
(1) 高频词与低频词
- 自然语言中,大量的单词只出现过一次或几次(称为“长尾单词”)。
- 高频词如“the”、“is”、“of”占据了语料库的大部分词频,但信息量较少。
- 低频词信息丰富,但在整个语料库中数量很少。
(2) 词汇覆盖问题
- 齐普夫定律表明,用少量的高频词可以覆盖大部分的语料。
- 示例:
- 前 1000 个高频单词可能覆盖文本中 80% 的单词出现次数。
(3) 数据稀疏问题
- 长尾单词的存在使得构建语言模型时会面临数据稀疏问题,许多低频词甚至在训练集中没有出现。
局限性
- 不能解释所有语言中的词频分布规律
- 对长尾单词的预测能力有限
- 无法直接量化单词的语义贡献
等价于
其中α是刻画分布的指数,c是常数。 这告诉我们想要通过计数统计和平滑来建模单词是不可行的, 因为这样建模的结果会大大高估尾部单词的频率,也就是所谓的不常用单词。 那么其他的词元组合,比如二元语法、三元语法等等,又会如何呢? 我们来看看二元语法的频率是否与一元语法的频率表现出相同的行为方式。
1 | |
这里值得注意:在十个最频繁的词对中,有九个是由两个停用词组成的, 只有一个与“the time”有关。 我们再进一步看看三元语法的频率是否表现出相同的行为方式。
1 | |
最后,我们直观地对比三种模型中的词元频率:一元语法、二元语法和三元语法。
1 | |
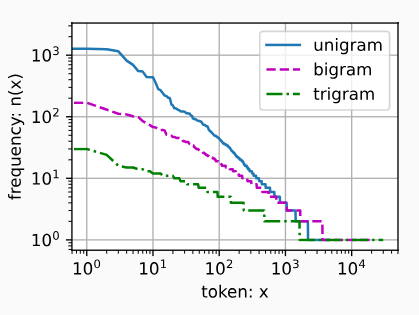
总结
- 除了一元语法词,单词序列似乎也遵循齐普夫定律
- 词表中n元组的数量并没有那么大,这说明语言中存在相当多的结构, 这些结构给了我们应用模型的希望
- 很多n元组很少出现,这使得拉普拉斯平滑非常不适合语言建模。 作为代替,我们将使用基于深度学习的模型
读取长序列数据

随机采样
在随机采样中,每个样本都是在原始的长序列上任意捕获的子序列。 在迭代过程中,来自两个相邻的、随机的、小批量中的子序列不一定在原始序列上相邻。 对于语言建模,目标是基于到目前为止我们看到的词元来预测下一个词元, 因此标签是移位了一个词元的原始序列。
缺点:
- 缺乏上下文连续性
- 数据冗余问题
- 训练样本分布不均匀
- 时间序列的顺序性丢失
- 不适合生成式任务
- 模型收敛较慢
- 随机性可能导致结果不稳定
1 | |
封装类
随机采样:用于需要数据多样性、上下文依赖性较低的任务。
顺序采样:用于需要捕获序列上下文的任务,例如语言建模或时间序列预测。
1 | |
封装类
1 | |